Integration
Nomenclature is made available under a Creative Commons Attribution License (CC-BY).
This is made possible through an agreement between the Canadian Heritage Information Network (CHIN) and Nomenclature’s publisher, Rowman & Littlefield.
You are free to share or adapt Nomenclature in respect of the CC-BY license as long as the source of the content is acknowledged as follows:
- © Rowman & Littlefield and Government of Canada, Canadian Heritage Information Network.
In circumstances where providing the full attribution statement above is not technically feasible, the use of Nomenclature URIs (e.g. https://nomenclature.info/nom/1090) is adequate as an attribution.
Please see the “Terms and Conditions of Use”.
Web services
SPARQL endpoint
The Nomenclature SPARQL endpoint allows exploration of the dataset and output in a variety of formats. Sample queries are provided as examples to get you started using SPARQL.
API
Nomenclature API
The Nomenclature API offers system developers a more conventional method to query the Nomenclature dataset, without requiring deep knowledge of the semantic data model. The 12 endpoints listed below return predefined responses in a JSON or XML format.
- /concepts - Get all concepts
- /concepts/{conceptId} - Get a concept by ID
- /concepts/{conceptId}/labels - Get all labels of a concept
- /concepts/{conceptId}/siblings - Get all siblings of a concept
- /contributors - Get all term contributors
- /contributors/{agentId} - Get a term contributor by ID
- /citations - Get all bibliography citations
- /citations/{bibId} - Get a bibliography citation by ID
- /revisions - Get all change notes
- /revisions/{changeNoteId} - Get a change note by ID
- /search - Search concepts by keyword
- /void - Get dataset description
For further information on API request parameters and response schema, see the API documentation.
Nomenclature Reconciliation Service
The Nomenclature Reconciliation Service (https://nomenclature.info/api/v1/reconcile) is an API intended to be used with external data integration tools that follow the Reconciliation Service API protocol, such as OpenRefine, a free, open source tool for data cleaning, transformation and enhancement.
This service consists of a semiautomated process that suggests matches between your museum’s object name data and Nomenclature vocabulary. For example, for a museum’s object name “ankle bracelet”, the service would recommend a list of potential matches from Nomenclature, and the user could select “anklet” as the closest match. After these matches are established, the service enables you to add any or all of the following Nomenclature data into your museum’s data:
- IDs
- Preferred terms in all available languages
- Alternative terms in all available languages
- Definitions in English and French
- Direct parent's preferred terms in English and French
Embedding Nomenclature concepts in your website
Some museums or collections management software vendors may wish to embed a view of the Nomenclature concepts within their own online tools, using stylesheets (CSS) to match the look and layout of their own web pages. To do this, web developers need to:
- create a div with a class='nomenclature'. This is mandatory
- specify the id of the term you want to display: data-id. This is the id you will find in the URL under the parameter id. For example, Chair is id 1090, https://page.nomenclature.info/parcourir-browse.app?lang=en&id=1090&wo=I&ws=CA. This parameter in the div is mandatory
- specify the lang: data-ui_lang (en, fr)
- the default is english (en value)
- specify the type: data-type (data, ref, all),
- the data-type “data” retrieves the data as you would see it on the first tab “Nomenclature” of the page https://page.nomenclature.info/parcourir-browse.app?lang=en&id=1090&wo=I&ws=CA
- the data-type “ref” retrieves the other references as you would see it on the second tab “Other references to this concept” of the page https://page.nomenclature.info/parcourir-browse.app?lang=en&id=1090&wo=I&ws=CA
- the data-type “all” retrieves all data “data” and “ref” in one request. This is the default value.
- specify the linguistic variant: data-ling_var (CA, INT),
- the data-ling_var “CA” retrieves the data in the Canadian linguistic variant
- the data-ling_var “INT” retrieves the data in the International linguistic variant. This is the default value
- specify the data-client_id (the email address of the organization or individual using the service, which we may use to notify you if we plan to make changes to this service that may disrupt usage).
- call the nomenclature javascript
- <script async src='https://page.nomenclature.info/js/inc-nomenclature-term.js'></script>
- Note that we will manage two major versions of the javascript (maintaining the previous one).
- current : inc-nomenclature-term.js (preferred)
- current (versioned): inc-nomenclature-term-1.0.js
- previous one inc-nomenclature-term-0.1.js
- we encourage users to always use the current javascript (without version number) since the versioned javascript may stop working if we decommission previous versions.
Several calls can be combined on the same HTML page.
For example:
- <div class='nomenclature' data-client_id='test_client' data-id="1080" data-type="data" data-ui_lang="en"><p>Please wait for content to load...</p></div>
- <div class='nomenclature' data-client_id='test_client' data-id="1080" data-type="ref" data-ui_lang="en"><p>Please wait for content to load...</p></div>
- <div class='nomenclature' data-client_id='test_client' data-id="1080" data-type="all" data-ui_lang="fr"><p>Please wait for content to load...</p></div>
- <script async src='https://page.nomenclature.info/js/inc-nomenclature-term.js'></script>
The phrase "Please wait for content to load…" has been included to let users know that it may take a moment for the external Nomenclature data to load into the page. This phrase can be customized as needed.
Note: the render of the page will require your customized CSS to make it look like your own site.
Documentation
Semantic model documentation
The Semantic model documentation is relevant for audiences interested in using the SPARQL endpoint of Nomenclature, or downloading the full dataset in RDF/XML, Turtle or JSON-LD format.
Descriptive information about Nomenclature
Machine-readable information describing the Nomenclature dataset and ontology is provided to allow semantic agents to more easily find, register, summarize, analyze, and consume Nomenclature linked data. Information on Nomenclature’s content, structure, licensing, access, properties and classes, and basic statistics are included. The main ontology used in this descriptive file is the Vocabulary of Interlinked Datasets (VoID). The Data Catalog Vocabulary (DCAT), the Asset Description Metadata Schema (ADMS) and others are also used.
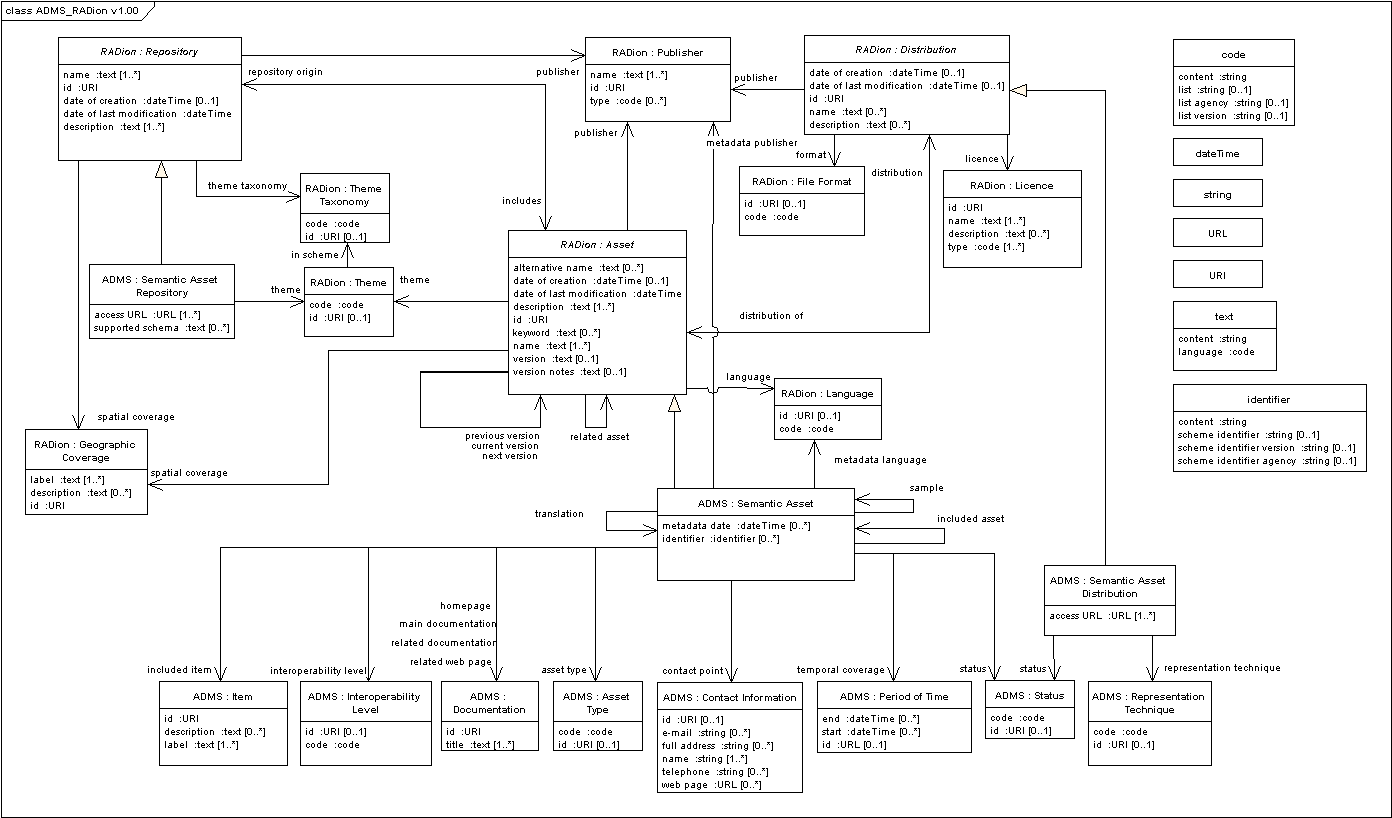{kind=link}
This file is updated nightly to refresh dynamic information such as number of concepts, number of triples, and date of last update. It is provided to facilitate automatic discovery.
The following files contain the same descriptive information about Nomenclature, but in different RDF serializations. The Turtle (.ttl) version includes comments and arrangement that make it more human-readable.
The following link will re-direct to either a Turtle, JSONLD, or RDF/XML file, depending on your HTTP header request. By default, the semantic HTML view will be returned.
Downloads
Downloading a current version
Nomenclature is continuously updated, and will no longer have named versions, as the printed volume did. The filename contains a date to help you identify when you last downloaded it. Data model information is provided in the Web Services and Documentation section below.
- RDF files
This is the recommended format for downloading Nomenclature. These files will be updated daily.
- Spreadsheets
If possible, use the RDF (above) instead of the spreadsheet. The language versions of the spreadsheets are identical, except for the sort order. These files will be updated daily. In order to ensure proper formatting, import the data as CSV instead of opening it directly in Excel or other software.
Downloading a conversion file
This file is not needed for new implementations. It may be useful as an interim step for those who previously implemented Nomenclature (e.g. Nomenclature 3.0 or 4.0) in their systems. Since the current version of Nomenclature excludes inverted order for terms made up of single words, this file containing all inverted-order terms (both single- and multiple-word terms) matched to the new Nomenclature IDs may help with conversion from systems that rely on the inverted order. After using this file to add the new Nomenclature IDs to your system, you will be able to use the IDs to update to the current version of Nomenclature.
- Excel Spreadsheet for conversion (724.8 KB) (.xls) or OpenOffice spreadsheet for conversion (396.2 KB) (.ods)
If you are implementing Nomenclature for the first time, use one of the current versions provided above, instead of this conversion file.
Téléchargement
Téléchargement d’une version courante
Puisque Nomenclature est constamment mis à jour, il n’y a plus de numéro de version apposé au titre, comme c’était le cas sur la couverture des volumes imprimés. Le nom du fichier contient, à titre de référence, une date qui permet d’identifier quand vous avez téléchargé la dernière fois celui-ci. Vous trouverez à la section Documentation et services Web (plus bas) des renseignements sur le modèle de données.
- Fichiers RDF
Il s’agit du format recommandé pour télécharger Nomenclature. Les fichiers seront mis à jour de façon quotidienne.
- Feuilles de calcul
Dans la mesure du possible, utilisez le fichier RDF ci-dessus plutôt que l’une des feuilles de calcul. À l’exception de l’ordre de tri, les feuilles de calcul sont identiques d’une langue à l’autre. Afin de vous assurer d'utiliser la mise en forme appropriée, veuillez importer les données en CSV au lieu d'ouvrir directement le fichier dans Excel ou dans un autre logiciel.
Téléchargement du fichier de conversion
Ce fichier n’est pas nécessaire pour les nouvelles implémentations. Le fichier sert à faire le pont avec les versions antérieures de Nomenclature, c’est-à-dire Nomenclature 3.0 ou 4.0, auparavant implémentés dans leurs systèmes. Comme celle-ci n’offre pas l’affichage inversé des termes constitués d’un seul mot, vous pouvez télécharger, si votre système s’appuie sur ce type de tri, le fichier de conversion, lequel recense en ordre inversé tous les termes (simples et composés) qui correspondent aux nouveaux identifiants de la version actuelle de Nomenclature. Après leur ajout à votre système, vous pourrez utiliser ces identifiants pour mettre à jour Nomenclature vers sa version actuelle.
Si vous implémentez Nomenclature pour la première fois, téléchargez la version actuelle (liens fournis plus haut) plutôt que le fichier de conversion.
- Date modified: